Introduction
Software programs often contain multiple components that act as subsystems, where each component operates in one or more trusted domains. For example, one component may have access to the file system but lack access to the network, while another component has access to the network but lacks access to the file system. Distrustful decomposition and privilege separation [[Dougherty 2009]] are examples of secure design patterns that recommend reducing the amount of code that runs with special privileges by designing the system using mutually untrusting components.
When components with differing degrees of trust share data, the data are said to flow across a trust boundary. Because Java allows components under different trusted domains to communicate with each other, data can be transmitted across a trust boundary. Furthermore, a Java program can contain both internally developed and third-party code. Data that are transmitted to or accepted from third-party code also flow across a trust boundary.
While software components can obey policies that allow them to transmit data across trust boundaries, they cannot specify the level of trust given to any component. The deployer of the application must define the trust boundaries with the help of a system-wide security policy. A security auditor can use that definition to determine whether the software adequately supports the security objectives of the application.
Third-party code should operate in its own trusted domain; any code potentially exported to a third-party — such as libraries — should be deployable in well-defined trusted domains. The public API of the potentially-exported code can be considered to be a trust boundary. Data flowing across a trust boundary should be validated when the publisher lacks guarantees of validation. A subscriber or client may omit validation when the data flowing into its trust boundary is appropriate for use as is. In all other cases, inbound data must be validated.
Malicious Data
Data received by a component from a source outside the component's trust boundary may be malicious. Consequently, the program must take steps to ensure that the data are both genuine and appropriate.

These steps can include the following:
Validation: Validation is the process of ensuring that input data fall within the expected domain of valid program input. For example, not only must method arguments conform to the type and numeric range requirements of a method or subsystem, but also they must contain data that conform to the required input invariants for that method.
Sanitization: In many cases, the data may be passed directly to a component in a different trusted domain. Data sanitization is the process of ensuring that data conforms to the requirements of the subsystem to which they are passed. Sanitization also involves ensuring that data also conforms to security-related requirements regarding leaking or exposure of sensitive data when output across a trust boundary. Sanitization may include the elimination of unwanted characters from the input by means of removal, replacement, encoding or escaping the characters. Sanitization may occur following input (input sanitize) or before the data is passed to across a trust boundary (output sanitization). Data sanitization and input validation may coexist and complement each other. Refer to the related guideline IDS01-J. Sanitize data passed across a trust boundary for more details on data sanitization.
Canonicalization and Normalization: Canonicalization is the process of lossless reduction of the input to its equivalent simplest known form. Normalization is the process of lossy conversion of input data to the simplest known (and anticipated) form. Canonicalization and normalization must occur before validation to prevent attackers from exploiting the validation routine to strip away illegal characters and thus constructing a forbidden (and potentially malicious) character sequence. Refer to the guideline IDS02-J. Normalize strings before validating them for more details. In addition, ensure that normalization is performed only on fully assembled user input. Never normalize partial input or combine normalized input with non-normalized input.
For example, POSIX file systems provide a syntax for expressing file names on the system using paths. A path is a string which indicates how to find any file by starting at a particular directory (usually the current working directory), and traversing down directories until the file is found. Canonical paths lack both symbolic links and special entries such as '.' or '..', which are handled specially on POSIX systems. Each file accessible from a directory has exactly one canonical path, along with many non-canonical paths.
In particular, complex subsystems are often components that accept string data that specifies commands or instructions to a the component. String data passed to these components may contain special characters that can trigger commands or actions, resulting in a software vulnerability.
Examples of components which can interpret commands or instructions:
- Operating system command interpreter (see guideline IDS06-J. Prevent OS Command Injection)
- A data repository with an SQL-compliant interface (see guideline IDS07-J. Prevent SQL Injection)
- XML parser (see guideline IDS08-J. Prevent XML Injection)
- XPath evaluators (see guideline IDS09-J. Prevent XPath Injection)
- A SAX (Simple API for XML) or a DOM (Document Object Model) parser (see guideline IDS10-J. Prevent XML external entity attacks)
- Lightweight Directory Access Protocol (LDAP) directory service (see guideline IDS11-J. Prevent LDAP injection)
- Script engines (see guideline IDS12-J. Prevent code injection)
Many rules address proper filtering of untrusted input, especially when such input is passed to a component that can interpret commands or instructions. For example, see IDS08-J. Prevent XML Injection.
When data must be sent to a component in a different trusted domain, the sender must ensure that the data is suitable for the receiver's trust boundary by properly encoding and escaping any data flowing across the trust boundary. For example, if a system is infiltrated by malicious code or data, many attacks are rendered ineffective if the system's output is appropriately escaped and encoded. Refer to the guideline IDS04-J. Properly encode or escape output for more details.
Sensitive Data
A system's security policy determines which information is sensitive. A component cannot define which information is sensitive; it can only provide support for handling information that may potentially be declared sensitive by the system administrator.
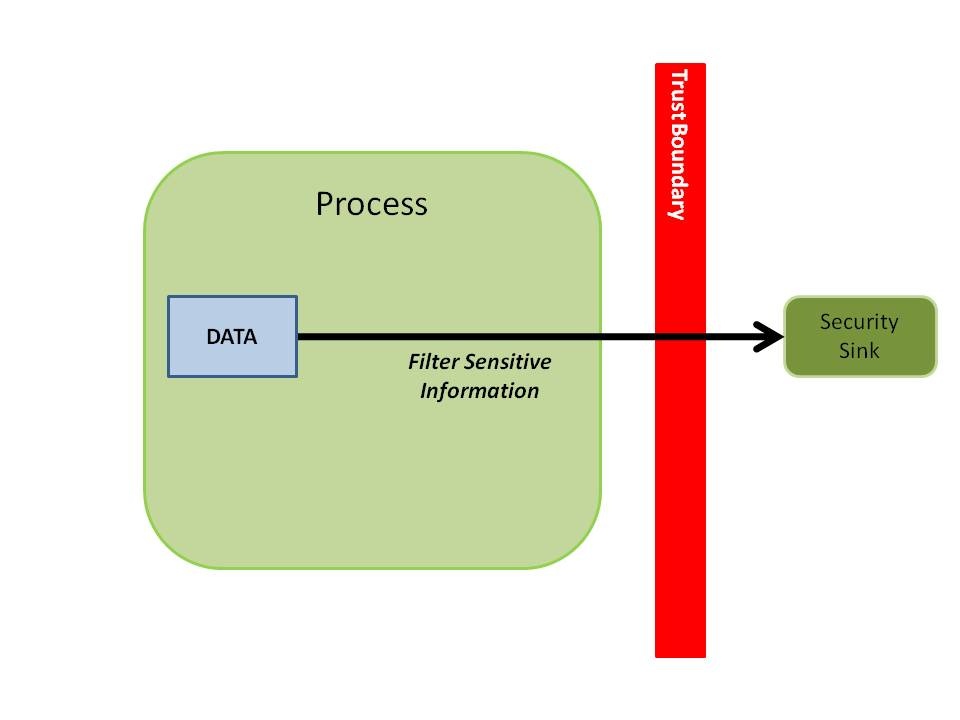
Java software components provide many opportunities to output sensitive information. Several rules address the mitigation of sensitive information disclosure, including EXC06-J. Do not allow exceptions to expose sensitive information and FIO08-J. Do not log sensitive information.
Guidelines
Risk Assessment Summary
Guideline |
Severity |
Likelihood |
Remediation Cost |
Priority |
Level |
|---|---|---|---|---|---|
IDS00-J |
high |
probable |
medium |
P12 |
L1 |
IDS01-J |
high |
probable |
medium |
P12 |
L1 |
IDS02-J |
high |
probable |
medium |
P12 |
L1 |
IDS03-J |
high |
probable |
medium |
P12 |
L1 |
IDS04-J |
high |
probable |
medium |
P12 |
L1 |
IDS05-J |
medium |
probable |
high |
P4 |
L3 |
IDS06-J |
high |
probable |
medium |
P12 |
L1 |
IDS07-J |
medium |
probable |
high |
P4 |
L3 |
IDS08-J |
medium |
probable |
medium |
P8 |
L2 |
IDS09-J |
medium |
probable |
medium |
P8 |
L2 |
IDS10-J |
medium |
probable |
medium |
P8 |
L2 |
IDS11-J |
high |
likely |
medium |
P18 |
L1 |
IDS12-J |
high |
likely |
medium |
P18 |
L1 |
IDS13-J |
low |
unlikely |
medium |
P2 |
L3 |
IDS14-J |
low |
probable |
medium |
P4 |
L3 |
IDS15-J |
low |
probable |
medium |
P4 |
L3 |
IDS16-J |
medium |
probable |
medium |
P8 |
L2 |
IDS17-J |
low |
unlikely |
high |
P1 |
L3 |
IDS18-J |
low |
probable |
high |
P2 |
L3 |
FIO15-J. Do not store excess or sensitive information within cookies when using Java Servlets The CERT Oracle Secure Coding Standard for Java IDS01-J. Sanitize data passed across a trust boundary