This coding standard is organized into 11 chapters that contain rules in specific topic areas followed by four appendices. Appendix A contains the bibliography. Appendix B lists the definitions of terms used throughout the standard. Appendix C lists the relationships between the rules of this standard and two other related guidelines: MISRA C++ 2008: Guidelines for the Use of the C++ Language in Critical Systems [MISRA 2008] and MITRE's Common Weakness Enumeration (CWE) [MITRE 2010]. Appendix D lists the risk assessments associated with all of the rules in the coding standard.
Most rules have a consistent structure. Each rule in this standard has a unique identifier, which is included in the title. The title and the introductory paragraphs define the rule and are typically followed by one or more pairs of noncompliant code examples and compliant solutions. Each rule also includes a risk assessment, related guidelines, and a bibliography (where applicable). Rules may also include a table of related vulnerabilities.
Identifiers
Each rule and recommendation (see Rules Versus Recommendations) is given a unique identifier. These identifiers consist of three parts:
- A three-letter mnemonic representing the section of the standard
- A two-digit numeric value in the range of 00 to 99
- A suffix that represents the associated language or platform.
- "-C" for the SEI CERT C Coding Standard
- "-CPP" for the SEI CERT C++ Coding Standard
- "-J" for the SEI CERT Oracle Coding Standard for Java
- "-PL" for the SEI CERT Perl Coding Standard
The three-letter mnemonic is used to group similar coding practices and to indicate which category a coding practice belongs to.
The numeric value is used to give each coding practice a unique identifier. Numeric values in the range of 00 to 49 are reserved for recommendations, and values in the range of 50 to 99 are reserved for rules. (The values used for the SEI CERT C Coding Standard are different.) Rules and recommendations are frequently referenced from the guidelines in this standard by their identifier and title.
Here are some example identifiers with an explanation of each:
- INT50-CPP Do not cast to an out-of-range enumeration value
- This identifier indicates a rule
- “INT” stands for the Integer category
- “50” is the unique identifier
- “-CPP” stands for the C++ language
- EXP00-J Do not ignore values returned by methods
- This identifier indicates a rule
- “EXP” stands for the Expressions category
- “00” is the unique identifier
- “-J” stands for the Java language
- FLP00-C. Understand the limitations of floating-point numbers
- This identifier indicates a recommendation
- “FLP” stands for the Floating Point category
- “00” is the unique identifier
- “-C” stands for the C programming language
Noncompliant Code Examples and Compliant Solutions
Noncompliant code examples illustrate code that violates the guideline under discussion. It is important to note that these are only examples, and eliminating all occurrences of the example does not necessarily mean that the code being analyzed is now compliant with the guideline.
Noncompliant code examples are typically followed by compliant solutions, which show how the noncompliant code example can be recoded in a secure, compliant manner. Except where noted, noncompliant code examples should contain violations only of the guideline under discussion. Compliant solutions should comply with all of the secure coding rules but may on occasion fail to comply with a recommendation.
Coding Conventions
Unless otherwise specified, all code should compile on a reasonably modern compiler, when it is following compliance with the standard. For example, you can require GCC's g++ to conform to the C++11 standard with the parameter --std=c++11.
Code that is only expected to run on a particular subset of platforms should have those platforms mentioned in the code's section header, e.g.: Compliant Solution (POSIX). Likewise, code that is only expected to run on more modern versions of C++ should indicate the oldest standard that supports them, e.g.: Compliant Solution (C++14).
In order to compile the code, you will need to include appropriate header files. For example, if the code invokes malloc(), you may need to include the cstdlib header.
Many code examples will contain ellipsis in comments. This indicates that the comment may be replaced by arbitrary code that satisfies the comment. A comment with only ellipsis suggests that the code may do anything.
Proper error handling is a controversial subject, and many applications and libraries provide their own idiosyncratic error handling mechanisms. See Rule 08. Exceptions and Error Handling (ERR) for our guidelines on handling errors. When our code detects that an error condition might have occurred, and handling that error condition is not endemic to the guideline itself, we will use the comment: /* Handle Error */. This comment implies that the error is somehow addressed, so that the code does not fall through. The code may abort, or fix the error somehow. For example:
char *str = malloc(10);
if (str == NULL) {
/* Handle Error */
}
/* ... str can not be NULL here. Work with str... */
Exceptions
Any rule or recommendation may specify a small set of exceptions detailing the circumstances under which the guideline is not necessary to ensure the safety, reliability, or security of software. Exceptions are informative only and are not required to be followed.
Risk Assessment
Each guideline in the CERT C++ Coding Standard contains a risk assessment section that attempts to provide software developers with an indication of the potential consequences of not addressing a particular rule or recommendation in their code (along with some indication of expected remediation costs). This information may be used to prioritize the repair of rule violations by a development team. The metric is designed primarily for remediation projects. It is generally assumed that new code will be developed to be compliant with the entire coding standard and applicable recommendations.
Each rule and recommendation has an assigned priority. Priorities are assigned using a metric based on Failure Mode, Effects, and Criticality Analysis (FMECA) [IEC 60812]. Three values are assigned for each rule on a scale of 1 to 3 for severity, likelihood, and remediation cost.
Severity—How serious are the consequences of the rule being ignored?
Value | Meaning | Examples of Vulnerability |
|---|---|---|
1 | Low | Denial-of-service attack, abnormal termination |
2 | Medium | Data integrity violation, unintentional information disclosure |
3 | High | Run arbitrary code |
Likelihood—How likely is it that a flaw introduced by ignoring the rule can lead to an exploitable vulnerability?
Value | Meaning |
|---|---|
1 | Unlikely |
2 | Probable |
3 | Likely |
Detectable—Can a static analysis tool automatically determine if code violates this guideline with high accuracy and precision?
Repairable—Can an automated repair tool reliably fix an alert by making local changes, and can the repair be guaranteed not to break the code even if the alert is a false positive? (There might exist a small set of cases that the tool cannot repair, but the tool can reliably identify these cases.)
In the context of automated repair, the phrase "break the code" requires more elaboration. We posit that noncompliant and un-repaired code currently works for some subset of inputs, which we would deem "expected inputs". To be noncompliant, there must also exist "unexpected inputs" that trigger the noncompliant code to do something unintended. This might be undefined behavior or simply unexpected or counter-intuitive behavior, such as producing an inaccurate mathematical result. For a repair to not break the code, the repaired code must exhibit the same behavior for all the expected inputs and only change behavior for some or all of the unexpected inputs. The changed behavior could be to signal an error condition, using whatever error-handling mechanism the code has adopted.
This definition of a repair differs from a refactor, which we define as a modification of the code that changes no behavior. That is, the refactored code behaves on both expected and unexpected inputs the same as the un-refactored code. If code can be automatically refactored to comply with a rule without changing its behavior on any inputs, that rule is automatically repairable (even though any such modification would be a refactor rather than a repair).
An automated repair tool does not need to know the developer's intent of any lines of code when repairing them. But it can be informed about idiosyncratic general details about the source code's conventions. One example would be whether assertions are disabled in production code. Knowing of such details is necessary if the repair tool must make code changes involving assertions.
The Detectable and Repairable questions are combined into a single Remediation Cost metric value that ranges from 1 to 3,
| Automatically... | Not Repairable | Repairable |
|---|---|---|
| Not Detectable | 1 | 2 |
| Detectable | 2 | 3 |
This Remediation Cost metric value, along with the Priority and Severity values are then multiplied together for each rule. This product provides a measure that can be used in prioritizing the application of the rules. The products range from 1 to 27, although only the following 10 distinct values are possible: 1, 2, 3, 4, 6, 8, 9, 12, 18, and 27. Rules and recommendations with a priority in the range of 1 to 4 are Level 3 rules, 6 to 9 are Level 2 , and 12 to 27 are Level 1 . The following are possible interpretations of the priorities and levels.
Priorities and Levels
Level | Priorities | Possible Interpretation |
|---|---|---|
L1 | 12 , 18 , 27 | High severity, likely, inexpensive to repair |
L2 | 6 , 8 , 9 | Medium severity, probable, medium cost to repair |
L3 | 1 , 2 , 3 , 4 | Low severity, unlikely, expensive to repair |
Specific projects may begin remediation by implementing all rules at a particular level before proceeding to the lower priority rules, as shown in the following illustration:
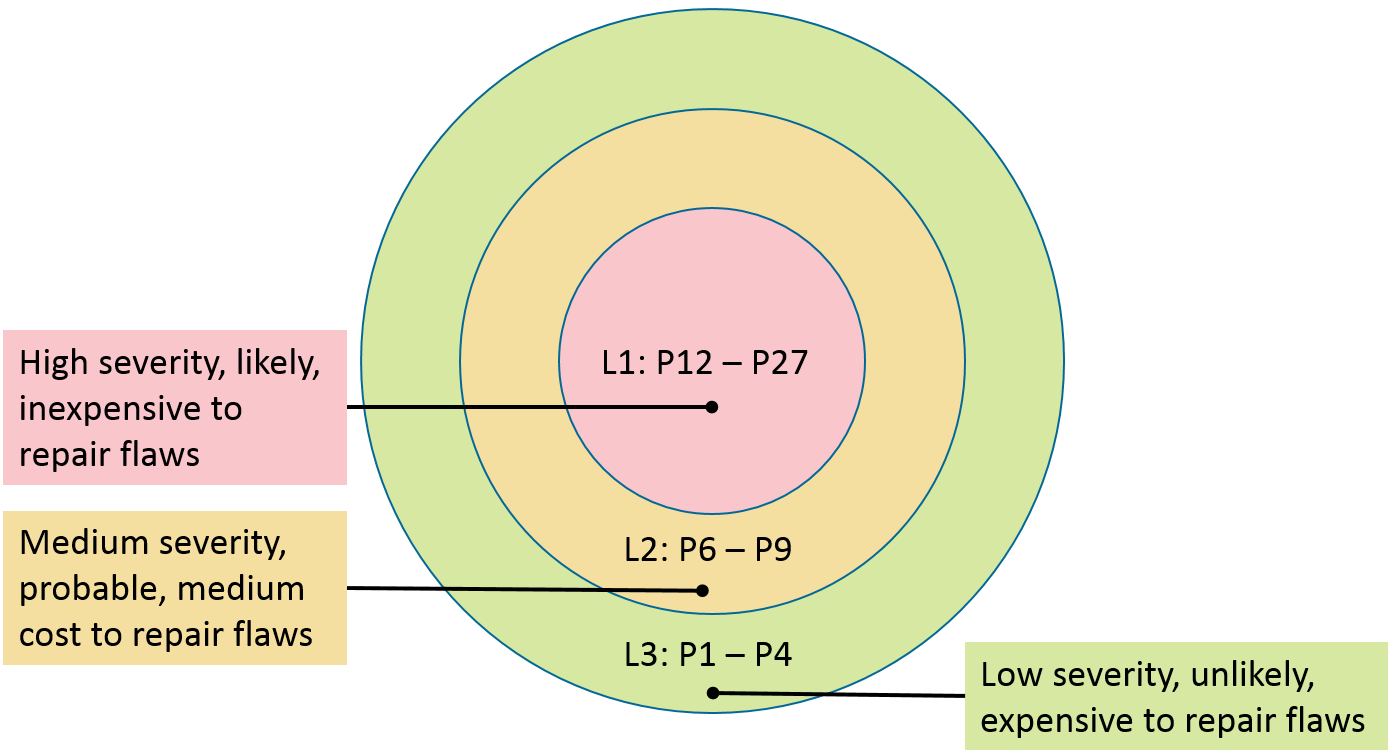
Recommendations are not compulsory and are provided for information purposes only.
Automated Detection
On the wiki, both rules and recommendations frequently have sections that describe automated detection. These sections provide additional information on analyzers that can automatically diagnose violations of coding guidelines. Most automated analyses for the C++ programming language are neither sound nor complete, so the inclusion of a tool in this section typically means that the tool can diagnose some violations of this particular rule. The Secure Coding Validation Suite can be used to test the ability of analyzers to diagnose violations of rules from ISO/IEC TS 17961:2013, which is related to the rules in the SEI CERT C Coding Standard.
- provided by the vendors
- determined by CERT by informally evaluating the analyzer
- determined by CERT by reviewing the vendor documentation
Where possible, we try to reference the exact version of the tool for which the results were obtained. Because these tools evolve continuously, this information can rapidly become dated and obsolete.
Related Vulnerabilities
The risk assessment sections on the wiki also contain a link to search for related vulnerabilities on the CERT website. Whenever possible, CERT Vulnerability Notes are tagged with a keyword corresponding to the unique ID of the coding guideline. This search provides you with an up-to-date list of real-world vulnerabilities that have been determined to be at least partially caused by a violation of this specific guideline. These vulnerabilities are labeled as such only when the vulnerability analysis team at the CERT/CC is able to evaluate the source code and precisely determine the cause of the vulnerability. Because many vulnerability notes refer to vulnerabilities in closed-source software systems, it is not always possible to provide this additional analysis. Consequently, the related vulnerabilities field tends to be somewhat sparsely populated.
Related vulnerability sections are included only for specific rules in this standard, when the information is both relevant and interesting.
Related Guidelines
The related guidelines sections contain links to guidelines in related standards, technical specifications, and guideline collections such as Information Technology—Programming Languages, Their Environments and System Software Interfaces—C Secure Coding Rules [ISO/IEC TS 17961:2013]; Information Technology—Programming Languages —Guidance to Avoiding Vulnerabilities in Programming Languages through Language Selection and Use [ISO/IEC TR 24772:2013]; MISRA C++ 2008: Guidelines for the Use of the C++ Language in Critical Systems [MISRA C++:2008]; and CWE IDs in MITRE’s Common Weakness Enumeration (CWE) [MITRE 2010].
You can create a unique URL to get more information on CWEs by appending the relevant ID to the end of a fixed string. For example, to find more information about "CWE-192: Integer Coercion Error," you can append 192.html to http://cwe.mitre.org/data/definitions/ and enter the resulting URL in your browser: http://cwe.mitre.org/data/definitions/192.html.
The other referenced technical specifications, technical reports, and guidelines are commercially available.
Bibliography
Most guidelines have a small bibliography section that lists documents and sections in those documents that provide information relevant to the guideline.
9 Comments
David Svoboda
Nov 01, 2016This page has a lot of overlap with the Rules Versus Recommendations page. How to resolve?
Aaron Ballman
Nov 01, 2016Agreed; we should probably combine them into a single page (probably getting rid of Rules vs Recommendations), esp since we don't have Recommendations for the C++ space right now.
David Svoboda
Nov 01, 2016The rule vs rec distinction is worth keeping, since we will (eventually) have recommendations. That aside, merging into a single page is a good idea. I suspect a better idea is for the Rules vs Recs page to only focus on that issue, and lose everything else to this page.
David Svoboda
Nov 02, 2016Shouldn't 'Related Guidelines' also cite the related CERT C & Java rules? I thought there would be many more standards in section D.
Aaron Ballman
Nov 02, 2016I suppose the CERT C rules should be listed there, but Java isn't related except that we wrote it and it's about security stuff (java and C++ don't share a particularly strong relationship as far as programmers usually care).
David Svoboda
Nov 02, 2016[IEC 60812] link should point to C++ bibliography, not C bib.
David Svoboda
Nov 02, 2016The Automated Detection and Related Vulnerabilities sections have traditionally been removed for the book. So should the corresponding sections here.
Robert Schiela
Jan 05, 2017Rather than removing the corresponding sections, I've changed them to explicitly say "on the wiki". That way, people reading the published version will know that the material exists somewhere.
Hubert Bugaj
Apr 17, 2017Shouldn't remediation cost be reversed? If the detection and correction is automatic then the cost should be lower.