...
| Wiki Markup |
|---|
The zip algorithm is capable of producing very large compression ratios \[[Mahmoud 2002|AA. References#Mahmoud 02]\]. Figure 2-1 shows a file that was compressed from 148MB to 590KB, a ratio of more than 200 to 1. The file consists of arbitrarily repeated data: For example, a file consisting of alternating lines of _a_ characters and _b_ characters can achieve a compression ratio of more than 200 to 1. Even higher compression ratios can be easily obtained using input data that is targeted to the compression algorithm, or using more input data (that is untargeted), or other compression methods. |
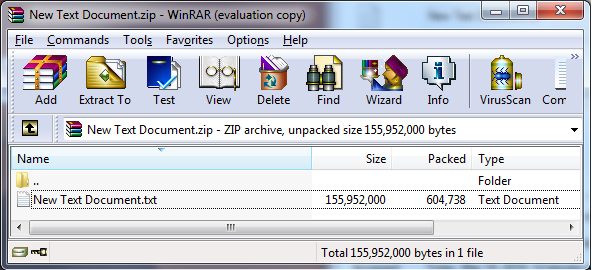
Any entry in a zip file whose uncompressed file size is beyond a certain limit must not be uncompressed. The actual limit is dependent on the capabilities of the platform.This rule is a specific instance of the more general rule MSC05-J. Do not exhaust heap space.
Noncompliant Code Example
This noncompliant code fails to check the resource consumption of the file that is being unzipped. It permits the operation to run to completion or until local resources are exhausted.
| Code Block | ||
|---|---|---|
| ||
static final int BUFFER = 512;
// ...
// external data source: filename
BufferedOutputStream dest = null;
FileInputStream fis = new FileInputStream(filename);
ZipInputStream zis = new ZipInputStream(new BufferedInputStream(fis));
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
System.out.println("Extracting: " + entry);
int count;
byte data[] = new byte[BUFFER];
// write the files to the disk
FileOutputStream fos = new FileOutputStream(entry.getName());
dest = new BufferedOutputStream(fos, BUFFER);
while ((count = zis.read(data, 0, BUFFER)) != -1) {
dest.write(data, 0, count);
}
dest.flush();
dest.close();
zis.closeEntry();
}
zis.close();
|
Compliant Solution
In this compliant solution, the code inside the while loop tracks the uncompressed file size of each entry in a zip archive while extracting the entry. It throws an exception if the entry being extracted is too large — about 100MB in this case. We do not use the ZipEntry.getSize() method because the value it reports is not reliable.
| Code Block | ||
|---|---|---|
| ||
static final int TOOBIG = 0x6400000; // 100MB
// ...
// write the files to the disk, but ensure that the file is not insanely big
int total = 0;
 dest = new BufferedOutputStream(fos, BUFFER);
 while (total <= TOOBIG && (count = zis.read(data, 0, BUFFER)) != -1) {
   dest.write(data, 0, count);
   total += count;
 }
 dest.flush();
 dest.close();
if (total > TOOBIG){
    throw new IllegalStateException("File being unzipped is huge.");  }
 // ...
|
Risk Assessment
Rule | Severity | Likelihood | Remediation Cost | Priority | Level |
|---|---|---|---|---|---|
IDS04-J | low | probable | high | P2 | L3 |
Related Guidelines
CWE-409. Improper handling of highly compressed data (data amplification) | |
Secure Coding Guidelines for the Java Programming Language, Version 3.0 | Guideline 2-5. Check that inputs do not cause excessive resource consumption |
Bibliography
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="8983fd52c90a0bb9-11dcb320-4cd34ad5-b13f83fa-31c6eff05ac2658a4c076cd6"><ac:plain-text-body><![CDATA[ | [[Mahmoud 2002 | AA. References#Mahmoud 02]] | [Compressing and Decompressing Data Using Java APIs | http://java.sun.com/developer/technicalArticles/Programming/compression/] | ]]></ac:plain-text-body></ac:structured-macro> |
...